1 Natural Language Processing as a Discipline
Natural language processing (NLP) is the discipline of designing and using computer programs to analyze or generate human language. Human language is an essential tool for expressing ideas, but it is also very diverse. On top of the differences in words and sentence structure of different groups, there are also differences that depend on how language is being used. Language can be formal or informal, technical or nontechnical, and occurs in a growing variety of forms from brief messages (like “tweets”) to entire books. Another distinction is between structured data and unstructured data, sometimes called “free text”. Structured text is where the fields of a table or record contain only a single phrase and the range of possible values is determined by the type of record. An example of structured text would be the fields of a database, which might include things like the name of the author, title, subject headings, and the publisher. An example of structured speech would be the phrase-level responses collected by an Interactive Voice Recognition system as it tries to route your call. Unstructured text is where the text contains one or more complete phrases or sentences, without an explicit indication about their intended use or interpretation. Examples of unstructured text are newspaper articles or a physicians’ clinical notes. Examples of unstructured speech would be audio recordings of conversations or speeches.
Many documents contain both structured and unstructured text. Figure 1.1. shows examples of both types taken from the website of a gaming platform, Steam[1]. The text on the left contains structured data provided by the organizers, while the text on the right is the first sentence of a review posted by a website user.
| Some structured text | Some unstructured text |
| Title: Dota 2 Genre: Action, Free to Play, Strategy Developer: Valve Publisher: Valve Release Date: Jul 9, 2013 RECENT REVIEWS: Mostly Positive (6,921) ALL REVIEWS: Very Positive (1,004,927) |
I started playing this game back when it was a mod on warcraft 3, it was great then, the community was ayy ok, not so bad, a little toxic but not too toxic…as the years went by I moved out from my parents house and had less time to play the game I had become addicted to, the game I would spend my Friday and Saturday night doing whilst the normal kids were out getting drunk on there 18th birthday. |
Unstructured text can give valuable insights; for example, NLP can be used to automatically decide if opinions like these are negative or positive. Analyzing structured text can be useful for statistical analysis tasks, such as deciding which game genres are most popular or for building search applications for retrieving games or reviews. These differing degrees of structure will impact the methods needed to make sense of the data: the more structure, the less processing involved.
NLP is both a mature discipline going back to the 1950’s[2] and a rapidly evolving discipline, exploiting some of the most recent advances in Artificial Intelligence, such as Deep Learning. While the structures and meaning of natural language have not changed much, new applications and implementation strategies have emerged to exploit the growing availability of large amounts of natural language data. Early approaches to NLP were based on researchers’ own knowledge, or that of other experts, with limited amounts of evidence to validate the approach. Modern NLP often follows the following general pattern: Identify a real-world concern, obtain samples of relevant data, pre-process and mine data to suggest patterns and research questions, and then answer research questions or solve technical problems by finding functions that capture complex correlations among different aspects of the data and validating these models with statistical measures. For example, Figure 1.2 shows an example conceptualization of an important problem: discovering whether patients have experienced side effects while taking a medication that may not have been discovered during clinical testing when the drug was approved (and may not even have been yet reported to their medical provider).
| Conceptualization |
Example |
| Concern | New medications may have negative consequences that emerge after initial testing. |
| Data | Postings to social media by patients. |
| Patterns | Certain words reflect positive or negative opinions. |
| Question | What negative side effects (adverse drug events) are being mentioned most often? |
NLP methods combine ideas from computer science and artificial intelligence with descriptive accounts of language and behavior, as provided by the humanities and the social and natural sciences. Human languages most differ from programming languages because of the possibility of ambiguity. Ambiguity arises because individual words can have different senses (such as “duck” as a water fowl and “duck” as the action of moving away from something). Words can also have unrelated, nonliteral meanings when they occur together with other words, such as “to duck a question”. Ambiguity can also occur at the level of a sentence, as in “We saw a duck in the park”, where it is unclear whether the viewer or the viewed was in the park. We do not tend to notice ambiguities like these when we communicate, because usually the context makes the intended meaning clear. An exception are puns, which are humorous exactly because we notice both meanings at once. Figure 1.3 includes an example pun.
| Pun | Multiple meanings |
|
|
Another source of complexity is that language exists at multiple levels of abstraction at the same time. Language produced in context has a literal form (what was said or written) and an intended meaning, which can be explicit or can involve inference to obtain implicitly expressed meanings[3]. An example of this literal/non-literal ambiguity occurs with “Can you pass the duck?,” which has the literal form of a yes-no question, but is also used as a request.
To help address these multiple levels of meaning, the discipline of natural language processing draws upon insights from many disciplines including linguistics, mathematics, philosophy, sociology, and computer science. These disciplines have a long history of trying to explain linguistic phenomena or to provide an analysis of human behavior, based on text. (The first concordance of the Bible was created in 1230[4].) Today, insights from these earlier analyses have been used to specify properties of words and methods for identifying legal sequences of words. These insights have also helped us to identify some core tasks for language models such as determining whether a given sequence of words can be derived from the rules of a language, selecting among multiple possible derivations for a sequence, extracting semantic information from sequences, and determining whether accepting the truth of one expression of natural language requires accepting the truth of some other.
1.1 Applications of NLP
Natural language processing is both a method of science and of practical applications. Analyzing human language can help us learn about people who are the target of a product or service or to extract information from user-generated content, to inform the design of new products and services. Information extraction identifies concepts useful for other programs, such as looking for mentions of symptoms in a doctor’s notes to aid in decision support or to map what had been expressed as unstructured, free text into relations in a database (structured data). Language analysis can be a part of assessing the writing or the writer, such as to improve the grammar of a document or to measure a writer’s skill or knowledge. Generating human language can be a way of presenting structured information in a more understandable or personalized form.
NLP can also be a mechanism for qualitative research. Qualitative research is a method of gaining information from a target population typically by asking a sample to complete a carefully crafted survey and then looking for emergent themes. However, survey bias is always a risk; it is very hard to write questions to test a hypothesis without survey subjects being able to detect what the hypothesis is, which might easily affect their response. An alternative is to look for instances where people have expressed their views on a topic publicly. Social scientists, market researchers, and healthcare providers have been investigating what people have said in their posted reviews of products, services, and medicines through websites like Amazon.com, Yelp.com, and Drugs.com. In the next few sections, we will overview some specific examples and potential opportunities in three broad areas: applications to support social good, applications to support public health or health care, and applications to support business.
1.1.1 Applications for Social Good
There are many dangers in our world, including terrorists, bullies, and even ourselves (when our concerns become depression or anxiety.) The internet has become a place where many of these dangers first appear. In March 2019, there was a mass shooting in New Zealand in which at least 49 people died. According to investigations by journalists, the shooter had been posting to online message boards associated with violence as many as three years before the tragedy[5]. NLP has also been used to identify reports of natural disasters posted to Twitter.[6] We also face some smaller dangers such as poor hygiene in restaurants or intentional misinformation posted to reviews of consumer products and services. In each of these scenarios, NLP could play a role in early detection of such dangers by processing articles created by news services or the postings of the general public in online social media like Twitter, Facebook, and Reddit, much faster than people could. Research on the detection of fake reviews, hate speech and cyberbullying, and depression has been ongoing since 2009, and are now accurate more than three-quarters of the time[7].
In addition to helping keep people safe, NLP also has applications that can help people improve the quality of their lives. For example, there are efforts to help people with visual impairments by automatically translating visual information on the Web into non-visual information, such as a spoken description. There has also been an increasing interest in the creation of chatbots to support humanitarian causes. For example, in 2018, the Computer-Human Interaction (CHI) conference organized a Special Interest Group (SIG) meeting dedicated entirely to creating chatbots for social good. Examples of social good that were discussed include helping find donors to support worthy causes and helping promote social justice by allowing people to document and share their experiences with the police.
1.1.2 Applications for Public Health and Health Care
Public Health involves preventing illness; healthcare involves diagnosing and treating illness. Natural language processing applications related to these topics can help in the dissemination of knowledge about how to stay healthy and the development of new treatments by helping to find associations between diseases and treatments that span multiple published articles. NLP can call attention to consumer-reported problems with medications, treatments, or contaminated food – reports which might appear in social media before formal reports are submitted to government agencies, such as the FDA or the USDA in the United States. NLP is being used to improve health care quality by giving providers quantitative evidence of which treatments are most effective for particular populations of patients. It is still the case that there are clinically documented features and risk factors (such as smoking status or social determinants) that only appear in unstructured clinical notes in electronic health records, rather than in more easily processed data from structured checklists. There are some health conditions where the best treatment option is also dependent on the values or preferences of a patient, but to play a role in more shared decision-making, patients also need to have a good understanding of their condition and options. NLP methods can help assure that they have this understanding and that their concerns are being addressed, by providing descriptions in appropriate language or giving them more opportunities to obtain health information outside a clinical encounter.
In the future NLP may be able to improve the communication between providers and patients by allowing providers to “talk” to their medical records software and their patient at the same time – rather than appearing to remove their focus from the patient. Major health care providers and U.S. government research institutes (including the Mayo Clinic, Harvard Medical School and Massachusetts General Hospital, and the National Library of Medicine) have longstanding research units dedicated to NLP and have been leaders in the dissemination of software and data sets to advance the discipline. There have also been commercial enterprises dedicated to NLP in healthcare, such as TriNetX.
1.1.3 Applications for Business and Commercial Enterprises
Applications of NLP can be used to meet commercial objectives. A company might provide language services such as machine translation, abstraction, summarization or some type of document delivery. For example, starting in the 1970’s both LexisNexis and Westlaw began to provide computer-assisted legal research services for professionals; and now these companies provide access to more than 40,000 databases of case law, state and federal statutes, administrative codes, newspaper and magazine articles, public records, law journals, law reviews, treatises, legal forms, and other information resources. Banks and providers of financial services technology are using NLP to help detect fraud. (Ironically, this work has been helped by the availability of datasets derived from Enron employee email[8], following one of the most notorious cases of investment fraud in American history.) Or, a company might be interested in using NLP for keeping their customers engaged or providing them solutions targeted towards their expressed needs or buying habits. (Tasks such as these, as well as customer relationship management (CRM) and customer support, can be found in online job advertisements.) By using NLP, employers hope to automate tedious data entry tasks that require extracting data from unstructured sources such as email, customer support requests, social media profiles, service logs, and automatically populate contact record with individual and company names, email, and physical addresses. They might also want to more easily use data that has been collected in unstructured form, such as website text boxes or telephone calls recorded for quality assurance. Sometimes the goal is to improve customer engagement by answering common customer questions more quickly by deploying a chatbot, rather than making people wait for a human to respond.
Businesses want to know whether customers like their products and why. Very accurate techniques have been developed to recognize whether people are positive or negative about a product based on the words they use in their reviews (called sentiment analysis or opinion mining). A similar strategy can be used for other classification tasks. For example, marketing expert Anne Gherini, has observed that (her) “customers use different words, phrases, and sentence structures at different stages of the buying cycle. Whereas, they tend to use interrogatives such as “who”, “what”, and “why” in the early stages, they tend to use verbs such as “purchase”, “become”, “guarantee”, and “discuss” in later stages”[9]. These insights suggest that it would be useful to have automatic methods for processing email and other customer communications to predict that customer’s stage of the buying cycle (and hence how ready they might be to make a purchase) and even to help generate a reply correctly targeted to the stage. Using data from a variety of existing sources, one can use NLP tools to count the frequency of co-occurring words, phrases, or statistically related words to count potentially emergent themes, one of the fundamental methods of qualitative research[10].
1.2 Main Abstractions of Natural Languages
As just discussed, human language can be used to help solve a variety of problems. While human languages are very diverse, there are also many commonalities among languages that enable us to develop many generalizable models and tools. According to classical linguistics, the main levels of abstraction for language are syntax, semantics, and pragmatics[11]:
- Syntax comprises the rules, principles, and processes that appear to govern the structure of sentences, especially rules that might be common across human languages.
- Semantics comprises the interpretation of sequences of words into an expression or set of expressions that captures the entities, relations, propositions, and events in the “real world” they describe or to elements of some “world” created by humans (such as queries to a database). Semantics is what we talk about as “the meaning” of a sentence.
- Pragmatics comprises an understanding or representation of how language is used by people to do things, such as make requests or ask questions, or what language reveals about the knowledge or preferences of the people who use it. For example, the sentence “Can you pass the salt?” is not typically a yes-no question, it is a request.
Where language is compositional, smaller units (such as words and phrases) have well-formed meanings that combine in a systematic way to form the meanings of the larger sequences they comprise. An example of a compositional semantics might map each word or phrase onto a relation in a logic. So, “Anu ate a small apple” might be represented as: [person(p1) and name(p1,”Anu”) and small(o1) and apple(o1) and event(e1,eat) and agent(e1,p1) and object(e1,o1)]. By contrast, some expressions are idiomatic, forming what are sometimes called collocations or multiword expressions. These expressions are relatively fixed sequences of words that function together as a single word. Examples in English include “see the light at the end of the tunnel” which means to “see a future time that is better than the current one” or “bite off more than one can chew” which means to “have taken on a task one cannot achieve”. Another type of non-compositionality arises when we use sequences of common words to give names to organizations or events, such as “Educational Testing Service” or “The Fourth of July”.
Philosophers of language classify language along lines similar to linguists’ notions of syntax, semantics, and pragmatics. For example, J. L. Austin describes language in terms of a hierarchy of actions, beginning with the locution, which is what was said and meant, and corresponds to the physical act of uttering a specific word or sequence of words (the “phone”), as well as its intended interpretation as a sentence (the “pheme”) and its referring to specific objects and relations (the “rheme”). The interpretation of the locutions form the illocution which includes the intended interpretation of what was done (e.g. making a statement or asking a question). The final level comprises the perlocution, which is what happened as a result – (e.g. eliciting an answer). Both approaches begin with the word as the smallest unit of analysis, although new words can be formed from existing ones by adding prefixes and suffixes, a process that is known as derivational morphology. Morphology is also used to change the grammatical properties of a word, a process known as inflectional morphology.
The specific categories and properties that describe the syntax of a language form its grammar. Evidence for the existence of specific categories comes from the patterns of usage that native speakers find acceptable. Early work involved field studies – asking native speakers to classify sentences as good or not. Today we have additional resources: we can used published documents and datasets of sentences annotated with grammatical features as positive examples – and treat anything not covered by these resources as ungrammatical. Another source of grammaticality information are the papers written by linguists themselves which often have included examples of ungrammatical sentences marked with an asterisk (*)[12].
Unacceptability may be due to any of the levels of abstraction. Figure 1.4 includes some examples and the level where the inappropriateness occurs.
| Level of abstraction | Acceptable | Unacceptable |
| Morphology | Maryann should leave | *Maryann should leaving |
| Syntax | What did Bill buy | *What did Bill buy potatoes |
| Semantics | Kim wanted it to rain. | *Kim persuaded it to rain. |
| Pragmatics | Saying: “What time is it?” as a question; when the hearer does not think the speaker already knows the time. | *Saying: “What time is it?” as a question; when the hearer thinks the speaker already knows the time. |
Most of these judgements would be clear to someone who is fluent in English, except perhaps the example for pragmatics. Pragmatics relies on background information not contained in the sentence itself, so multiple scenarios are provided. The underlying background for the example is that it is only appropriate to ask a real question when it is likely that the person asking does not know the answer, because the intended effect of a normal question is to solicit new information. Questions can be used appropriately to do other things however, such as make complaints or indirectly solicit an explanation. A collection of sentences including both acceptable and unacceptable examples, including morphology, syntax, and semantics, is found in the Corpus of Linguistic Acceptability (CoLA). (Chapter 3 will describe the grammar for English as accepted by most modern work in NLP, which was derived from work in computational linguistics.)
1.2.1 Abstractions at the Word Level
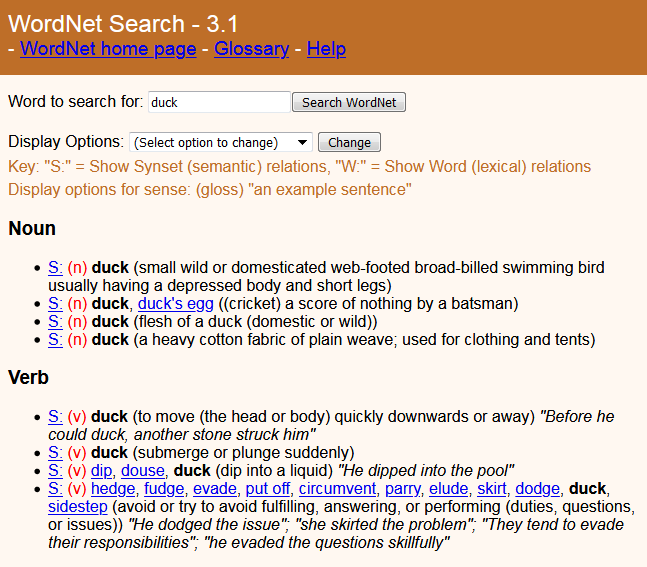
Words have a syntax and a semantics, and may also be categorized based on some aspect of their use. One very commonly used aspect is sentiment. Sentiment is the overall polarity of opinion expressed by the speaker, which might be positive, negative, or neutral. Sentiment is expressed through the choice of words that are conventionally associated with that polarity, which might differ for a specific domain. For example, a book might be “fascinating” (positive) or “predictable”. (We will consider sentiment analysis in greater detail in Chapter 3.) The syntax of a word includes its main part of speech (such as noun or verb) and subtypes of these categories, based on their properties, such as a plural noun, or a past tense verb. As mentioned above, there is no one standard set of categories, although there are sets of categories that have become standardized. Standardized sets of category labels are known as tagsets, and a specific example will be provided when we discuss English grammar. One can also describe categories as collections of features. In addition to properties like number and tense, a word type is characterized by the constraints or preferences it has for words or phrases that precede or follow it. For example, some nouns, like “bag” must be preceded by an article and are often followed by a modifier that says what holds, as in “a bag of rice”. (We will discuss word syntax in greater detail in Chapter 4). The semantics of a word is the concept or relation that the word would correspond to in the real world. Because of the existence of homonyms, the mapping from a word to semantics (or even syntax) requires information from the context (either surrounding sentences or a representation of the visible context) to determine the intended analysis. Figure 1.5 shows the entries for duck found in Wordnet 3.1[13], which contains four distinct noun senses and four verb senses for duck.
 |
1.2.2 Abstractions at the Phrase and Sentence Level
Words in sequences form phrases and sentences. The difference between a phrase and a sentence is that a phrase must describe a complete entity or property-value pair, but it does not fully describe an event or state of affairs. A sentence by contrast, will have a main predicate, typically a verb, and some number of arguments and modifiers. A simple example would be the declarative sentence: “The cat sat on the mat.” Regardless of whether it is true, it is complete because it says who did the sitting and where it sat. In English, we can also have passive sentences, such as “The mat was sat upon” which are also complete, even though who did the sitting is unknown. The phrase and sentence types of a language are determined in much the same way as its word level categories. Linguists may ask native speakers to judge the acceptability of combinations of words. They may also try replacing a whole sequence of words with some other sequence and ask about its acceptability, as a way of testing whether those sequences correspond to the same type of phrase.
Phrases and sentences have a syntax, semantics, and a pragmatic interpretation. They can also be labelled with general categories. One commonly used classification is by sentiment, which was discussed above as a word-level abstraction. The syntax of a phrase or sentence specifies the acceptable linear order of words, and the hierarchical structure of groups of words, which is called constituency. Both order and constituency constraints can be described by a grammar, using either a set of production rules, such as Context Free Grammar, or as a set of dependency relations among words. (We will discuss examples of grammars for English phrases and sentences in Chapter 4.) A parse tree represents a trace of a derivation of a sentence from a given grammar.
The semantics of a phrase can be shallow or deep. A shallow representation involves labeling the phrases of a sentence with semantic roles with respect to a target word, typically the main verb.
For example, the following sentence
The doctor gave the child a sticker.
would have roles labeled as follows:
[AGENT The doctor] gave [RECEPIENT the child] [THEME a sticker ].
A deep semantics of a phrase or a sentence is an expression in some formal logic or structured computational framework that maps the words onto the units of that framework. In a logic that would include terms and well-formed formulas, whereas a computational approach might use an ad hoc slot and filler structure (such as a record in Java or an object in Python or C).
The pragmatics of a phrase or a sentence captures how it is being used in context. We will discuss these in Chapter 6.
1.2.3 Abstractions above the Sentence Level
We can also consider language forming units larger than a single sentence. The larger units include paragraphs and documents, but also include structures derived from interactive communication, such as dialog or multi-party interaction. Unstructured representations include sets of discrete words or continuous (weighted) vectors of words, which ignore the order or syntactic structure within the original units. These representations are used for information retrieval where the goal is to facilitate matching rather than to extract information. Structured representations include ad hoc slot and filler representations, similar to what is done for single sentences, but meant to capture complex events described in say, a news article. Structured representations can also include tree or graph-like structures, where phrases or sentences combine to form higher order relations, such as question-answer, or cause-effect that can be represented as hierarchical structures based on semantics or rhetorical relations (e.g., justification or concession). Collections of such structures are contained in the Penn Discourse Treebank and Rhetorical Structure Theory Discourse Treebank, respectively.
1.3 Subtasks of Natural Language Processing
In computer science, qualitative insights have been expressed as both declarative representations (sets of facts) and processing models (procedures and functions). Early work relied on representations created entirely by hand, by highly trained experts, and used search algorithms to derive a solution. Now, one can often use input representations and processing models that have been created by algorithms whose parameters have been adjusted automatically using raw (or lightly processed) data. Moreover, this data is often made available for use by anyone and the algorithms also exist in open source libraries.
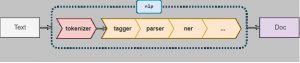
Pipelines for processing unstructured natural language start with the text (possibly including metadata, such as HTML tags) and convert it into a form that is usable by a software application before applying a sequence of algorithms that each perform a different automated analysis and create outputs, in stages. These stages may be defined independently or as a single networked architecture with layers that address specific tasks. Figure 1.6 illustrates the default pipeline used in spaCy, a widely used NLP software library [14]. First there is a process, called tokenization, where the boundaries between words are identified (usually when there is a space) and punctuation is removed. Tokenization typically also includes identifying the root form of a word (also called its type, or lexeme). The next steps enrich the input representation, such as by labelling individual words with their syntactic category (e.g. “’noun”), a process called part of speech tagging which is performed by a tagger. This process is normally followed by lemmatization (not shown) which involves identifying the root form of a word and syntactic attributes (such as past or plural). Then sequences of words from the text are labelled with their syntactic function (e.g., subject or object). This process is called parsing and is performed by a parser. Processing might stop here, or it might continue by recognizing and labelling specific expressions with a general semantic type, such as names of people, locations or times, by a process called named entity recognition (NER). Sometimes words, phrases, or sentences will also be annotated with a representation of their meaning.
 |
After the input sequence is suitably enriched, the result is a complex data structure that is represented in the figure as “Doc”. This structure can be used to form a descriptive analysis of a text (or set of texts), fed into another processes for automated categorization or used as input to a software application, such as a text summarization system. An NLP pipeline might also be extended to integrate the results with the results from previously processed sentences, such as to identify the overall rhetorical structure (e.g., one text might explain or elaborate upon another), or to identify when entities mentioned in multiple sentences are in fact talking about the same entity (a process called reference resolution). These latter steps are not standardized and are topics for current research and development.
Although many natural language tasks can be accomplished using existing software libraries, using them effectively still involves human judgement and skill. Only human judgement can determine what problems or opportunities are both worthy and feasible. The first task for many is to identify and obtain suitable data. If the data does not yet exist, one can plan a method for creating new data, such as through web-scraping or conducting a survey study. The difficulty of these tasks will vary across domains. Obtaining “personal information” such as health or financial records is the most difficult, because there are typically laws to protect the privacy of patients (e.g. HIPAA)[15] and safeguards must be put in place to prevent unintended breeches of security. Instead, one may need to develop methods using older data (the records of the dead are not protected) or data that has been de-identified and made public. After one has data, the next task is to select (or develop) methods for processing it that are appropriate to the amount of data. If there is only a small amount, then one might hand-craft the structures or rules for processing. Voice applications, such as chat bots, are often developed this way.
When there is a moderate amount of un-annotated data for a task, one can develop a phased strategy beginning with hand-annotation or data labelled with hand-written rules and then use the labelled data to train an algorithm to do the rest of the task. For problems with large quantities of existing data, there may be a way to interpret part of the data as a label for a task, such as the number of stars in a product review. Then one can train an algorithm to label other similar examples. Algorithms that learn strategies for labelling (or assigning a probability distribution to a set of possible labels) are what is meant by machine learning and the models they create include both statistical classifiers and neural networks. It is usually necessary to experiment with a variety of alternative learning strategies to see what works best, including reusing models from existing systems, or coding a moderate amount of data by hand and then using it to train a model to code a larger set. Classification-based approaches often treat the structures produced by NLP as input features, but classifiers can also be used to perform many of the tasks in the NLP pipeline. Open source data science workbench tools, such as Weka, allow one to compare different strategies easily, by providing most of the algorithms and configuration alternatives that one might want, without installing any additional software. Workbenches allow one to select data, algorithms, and parameter settings using simple menus and check boxes, and provide functions for analyzing or visualizing the results.
1.4 Resources for NLP: Toolkits, Datasets, and Books
The availability of resources for NLP has been increasing, to serve a wide range of needs. A recent search of software tool kits for NLP with updates with in the past 5 years yielded at least 11 different systems, spanning several programming languages and architecture (see Figure 1.7). A few organizations (AllenAI, Google, Microsoft, and Stanford) have created online demos that have helped people to understand some of the terminology of NLP (by providing concrete examples). Figure 1.8 lists some notable demos that provide word and sentence level analysis in real-time for examples submitted by visitors to the website, without creating an account or downloading any software.
Publicly available datasets are also propelling the field forward. Datasets have been collected from a variety of genres. The oldest collection of freely available text, spanning multiple genres, is the Brown Corpus. The largest public collection of cultural works is distributed by Project Gutenberg, which contains over 60,000 complete literary works in electronic form. The most widely used annotated data resource for NLP has been the Penn Treebank. The Linguistic Data Consortium distributes many NLP specific datasets, some openly and some for a licensing fee. Totally free datasets can be obtained from the Stanford Natural Language Processing Group, the Apache Software Foundation, the Amazon Open Data Registry, and Kaggle.com, to name a few. There are also online discussion groups devoted to the discussion of datasets themselves, e.g the Reddit forum, r/datasets.
In addition to the documentation for the software frameworks mentioned above, there are some notable books that include examples of NLP programming using specific programming languages. The book “Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit[16]” is freely available online under a Creative Commons License (CC-BY-NC-ND), in addition to its printed version. Other books (e.g. for Java or a tool like PyTorch) are offered as part of a monthly subscription service that often includes a free trial. One of them might be a good companion to this book.
| Name of Project | What it is |
| AllenNLP | PyTorch-based toolkit for most medium and high level NLP tasks; includes Elmo word vectors |
| ClearTK | UIMA wrappers for NL tools (Snowball stemmer, OpenNLP tools, MaltParser dependency parser, and Stanford CoreNLP) and UIMA corpus readers |
| FRED | Machine reading produces RDF/OWL ontologies and linked data from natural language sentences, includes Named Entity Resolution and Word-Sense Disambiguation, as a REST service or Python library |
| GATE | Java framework for most symbolic NLP tasks |
| Gensim | Python software library for topic modelling and similarity detection, with an embedded word2vec implementation |
| Natural language Tool Kit (NLTK) | Python software library for most symbolic and statistical NLP tasks with access to many corpora for many languages (widely used in education) |
| Scikit-learn | General Python toolkit for ML, but also has functions for text analytics (e.g., tokenization, classification) |
| spaCy | Industrial strength libraries for NLP, loadable via Conda or pip, but has only a dependency parser |
| Stanford CoreNLP | Java software library (with Python wrappers) for most symbolic NLP tasks; maintained by Stanford researchers (used in education and production systems) |
| SyntaxNet | Tensorflow-based toolkit for dependency parsing; created by Google |
| Textblob | Python libraries for most common NLP tasks; built from NLTK but somewhat easier to use, by Steven Loria |
| Tweet NLP | Python software for most NLP task, trained on Twitter data; older versions for Java 6 also available (now maintained by CMU researchers) |
| Weka | Java datamining software including many NLP tasks with GUI/API; maintained by researchers at the University if Waikato, NZ. Also has WekaDeeplearning4j |
| Software Demo | Location on the web |
| AllenNLP demos of semantic labelling, sentence labelling in several formats, reading comprehension, and semantic parsing | https://demo.allennlp.org/ |
| FRED demos of machine reading | http://wit.istc.cnr.it/stlab-tools/fred/demo/ |
| Google Parsey McParseface demo of dependency parsing | https://deepai.org/machine-learning-model/parseymcparseface |
| Stanford CoreNLP demos of word, phrase, and sentence level annotation in several formats | corenlp.run |
1.5 Outline of the Rest of this Book
This chapter presented an overview of the discipline of natural language processing. The goal was to convey both the scope of the discipline and some of the key application areas and knowledge-level abstractions. Chapter 2 will consider abstractions at the data and processing level, to overview the types of methods used to solve the subtasks of NLP. Chapter 3 presents an overview of English Syntax. Chapter 4 discusses grammars and parsing. Chapter 5 covers semantics and semantic interpretation. Chapter 6 presents modern benchmark tasks for language modelling, including grammaticality analysis and sentiment analysis. Chapter 7 covers the analysis of multi-sentential texts, including discourse and dialog. Chapter 8 covers various applications of, and methods for, text content analysis, including question answering and information extraction. Chapter 9 covers applications of, and methods for, text generation, including machine translation and summarization.
1.6 Summary
Natural language processing is a discipline that allows us to tap into one of the richest resources of human experience. It is hard to even imagine an area of social or commercial interest that does not result in artifacts containing natural language. Although natural languages and the purposes for which we use it are diverse, there are essential abstractions that are essential to all of them: words, sentences, syntax, semantics, and pragmatics that create an opportunity for creating generalizable methods for analyzing language. While the first NLP methods relied on small sets of examples and a high level of human expertise, there are now large sets of digitized data that have been made available for public use that makes methods based on large data sets and the latest advances in artificial intelligence feasible. Additionally, today there are many highly accurate, freely available software tools for analyzing natural language.
- Steam (2021) Dota 2 URL https://store.steampowered.com/app/570/Dota_2/ (Accessed June 2021). ↵
- Hutchins, J. (1998). Milestones in Machine Translation. No.4: The First Machine Translation Conference, June 1952 Language Today (13), 12–13 ↵
- Austin, J. L. (1962). How to Do Things with Words. Cambridge: Harvard University Press. ↵
- Fenlon, J.F. (1908). Concordances of the Bible. In The Catholic Encyclopedia. New York: Robert Appleton Company. Retrieved April 19, 2020 from New Advent: http://www.newadvent.org/cathen/04195a.htm ↵
- Mann, A., Nguyen, K. Gregory, K. (2019). Christchurch shooting accused Brenton Tarrant supports Australian far-right figure Blair Cottrell. Australian Broadcasting Corporation. Archived from the original on 23 March 2019. URL:https://web.archive.org/web/20190323014001/https://www.abc.net.au/news/2019-03-23/christchurch-shooting-accused-praised-blair-cottrell/10930632. ↵
- Maldonado, M., Alulema, D., Morocho, D. and Proaño, M. (2016). System for Monitoring Natural Disasters using Natural Language Processing in the Social Network Twitter. In Proceedings of the 2016 IEEE International Carnahan Conference on Security Technology (ICCST), pp. 1-6. ↵
- Zhang, Z., Robinson, D. and Tepper, J. (2018). Hate Speech Detection Using a Convolution-LSTM Based Deep Neural Network. In Proceedings of the 2018 World Wide Web Conference (WWW '18). ↵
- There are many datasets based on the Enron email data. One of the more recent and well-docmented versions is distributed by researchers at the University of British Columbia from their project website. URL: https://www.cs.ubc.ca/cs-research/lci/research-groups/natural-language-processing/bc3.html (Accessed June 2021) ↵
- Gherini, A. (2018). Natural Language Processing is Revolutionizing CRM. Published online August 14, 2018. URL: https://aithority.com/guest-authors/natural-language-processing-is-revolutionizing-crm/ Accessed January 2021. ↵
- Austin, Z., and Sutton, J. (2014). Qualitative Research: Getting Started. The Canadian Journal of Hospital Pharmacy, 67(6), 436–440. https://doi.org/10.4212/cjhp.v67i6.1406. ↵
- Silverstein, M. (1972). Linguistic Theory: Syntax, Semantics, Pragmatics. Annual Review of Anthropology, 1, 349-382. Retrieved April 19, 2020, from www.jstor.org/stable/2949248 ↵
- Warstadt, A., Singh, A. and Bowman, S. R. (2018). Neural Network Acceptability Judgments, arXiv preprint arXiv:1805.12471. ↵
- Princeton University (2020). WordNet: A Lexical Database for English. ↵
- spaCy.io, 2019. Language Processing Pipelines (Image) URL: https://spacy.io/usage/processing-pipelines Accessed April 2019. ↵
- Moore, W. and Frye, S. (2019). Review of HIPAA, Part 1: History, Protected Health Information, and Privacy and Security Rules. The Journal of Nuclear Medicine Technology 47: 269 - 272. ↵
- Bird, S., Klein, E., and Loper, E. (2021). Natural Language Processing with Python. URL:https://www.nltk.org/book/ Accessed January 2021. ↵
Structured data is data that resides in a fixed, labelled field of table or record.
Unstructured data is data that does not reside in a fixed, labelled field of table or record, such as the items in a bag, set or sequence.
Deep Learning is a subset of computing approaches based on artificial neural networks where the network architecture has been organized into several layers. The parameters of these models are learned from large sets of data (rather than being set by experts).
Ambiguity is where a word, phrase, or statement has more than one meaning. (Usually the context of usage will eliminate all but one of them.)
The physical act of uttering a sequence of words.
The intended meaning of an untterance, such as to make an assertion or a request.
The action or condition that results from an utterance, such as eliciting a response or causing anger or amusement.
Changes of word spelling that create a new word - either by changing the syntactic or semantic type.
Changes to the spelling of a word that change its properties, without resulting in an entirely new word, for example, adding "s" to indicate a plural or "ed" to indicate past tense.
Process of splitting sequences of characters into individual words.
Part of speech tagging is a process of labelling a word or each word in a sequence of words with a unique symbol from a fixed set, to capture the correct syntactic category or features of the word given its surrounding context.
Lemmatization is a process of identifying the correct root form of a word and its syntactic attributes.
Named entity recognition is a process of labelling words or multiword expressions with a type from an ontology of concepts, such as person, organization, location, or time.
