8 Question Answering, Text Retrieval, Information Extraction, & Argumentation Mining
This chapter considers two special cases of discourse: questions and arguments; and methods that support them: question-anwering, text retrieval, information extraction, and argumentation mining. In the traditional account of language, we distinguish three types of sentences: statements (declaratives), questions (interrogatives), and commands (imperatives). During an interaction among multiple people or people and a computer system, these types of sentences occur together to address the goals of information seeking (e.g., via question answering) or persuasion (e.g., argumentation). An overview each of these topics follows:
- Question Answering (QA), also known as information-seeking dialog, is a type of two-way interaction where the user controls the primary turns and the system responds. Such a system must first interpret the question and then create and deliver the response. Creating the response may be a relatively simple matter of finding an answer within a table (e.g., within a FAQ), or initiating a pipeline of processes to find the most relevant document and extract a response from the document.
- Text retrieval returns ranked lists of documents, but not an “answer”. For real-time QA, one needs a separate system to preprocess the documents to support search for a wide range of information needs, a task called information retrieval. When the documents are mostly unstructured text, we call it text retrieval.
- Information extraction finds a specific answer to address the focus of a question. Information extraction methods can also be applied to find all possible properties or relations mentioned in a text, either based on the main verb, or on predefined entity types, such as person, location, and time.
- Argumentation mining is a special case of information extraction where the extracted components have been defined to model the legal notion of an argument, such as claim, attack, and rebuttal.
We will consider both the characteristics of these types of discourse and the computational methods for achieving them in greater detail. However, first we will consider some interesting real-world examples.
8.1 Examples of question answering
Suppose that you wish to create a chatbot style front end to a general purpose search engine, such as provided by many smart speakers like Amazon’s Alexa or Apple’s Siri as well as the search boxes of modern browsers, such as Chrome. You would like it to process questions in context – which includes the time and place of the question. Sometimes it can answer with information drawn from static stored sources, like Wikipedia, but sometimes it must be able to access sources that change.
Figure 8.1 shows some examples of questions and replies from Chrome, on a Sunday in January, 2021 in Milwaukee, Wisconsin.
| Question | Response |
| When do the Bucks play? | Untailored table of the dates, times and opponent of four Milwaukee Bucks basketball games in the second half February, but none for the up coming week |
| Where is Milwaukee playing this week? | A tailored display (with team logo) of 4 games between Feb 3 and Feb 6 |
| Who beat the Bucks? | A tailored display of the score from yesterday’s game and a link to the entire schedule, with scores of past games. |
| Who beat Milwaukee this year? | The same display as above |
| Who owns the Bucks? | Untailored table of the coach, the ownership, the affiliations, etc, and a link to the Wikipedia page |
Now suppose that one wishes to create a tool to help the moderator of an online forum answer questions from cancer survivors. People can post their stories to a forum, including requests for information or advice, and forum members can also respond to each other. The moderator may chime in with the answer to a question if it has gone unanswered for too long or the best answer is missing. Sometimes the questions are answerable without more information; sometimes the best thing to do is to refer them to a healthcare provider. The challenges include: identifying requests for information,identifying whether the responses have adequately answered the question, and if necessary, finding and providing either a direct answer (if it is brief) or reference to a longer document that would contain the answer. One recent approach tested the idea of training a classifier to identify sentences that express an information need, extracting keywords from those sentences to form a query to a search engine to extract passages from the provider’s existing educational materials for patient. They study found that very few questions would be answerable from the educational documents, because they contained concepts outside the scope of the materials[1]. (For example, the patient might have already read the materials and found they did not address their concerns, e.g., how to cope with hair loss, or were too generic, and that is what motivated them to seek help from peers.)
8.2 Question Answering
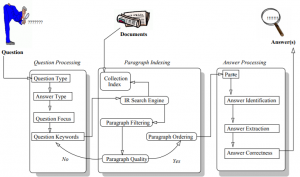
In a general dialog system, handling questions requires identifying that a clause in the dialog expresses a question, identifying the semantics of the question, such as the topic and any constraints, and identifying the expected answer type (EAT) of the question, such as a person, location, or description. The identified information is then used to decide how to address the question, which might be a direct answer, or an explanation of why the EAT is not provided. Sometimes frequently asked questions (FAQ) are known and their answers can be precomputed and stored so that they can be delivered quickly. Less frequent, but predictable, questions are often anticipated by document authors and included in the metadata stored with a document. The types of information typically found in metadata include the names of authors, the title, the date of publication, and several subject headings, which are terms from a controlled vocabulary. To answer a question, selected information from the metadata can be aggregated and used as input to a natural language generation system (see Chapter 9). Otherwise, novel or unexpected questions, which are sometimes referred to as “open domain” questions, can be answered by applying a pipeline of processes to extract an answer from a set of previously processed passages (paragraphs) created from a collection of documents or from a call to a general web search engine[2]. Figure 8.2 shows an example of a pipeline for complex question answering[3].
The QA pipeline shown in Figure 8.2 begins with classification to determine the question and answer types, which may require subtasks of “feature engineering” to identify important noun phrases (using named entity recognition), important relations between verbs and nouns (using semantic role labelling, or relation extraction) or to build vector representations (of the words or the whole question). These inputs are used for querying a search engine and for extracting information from retrieved texts. A search engine is a general purpose system for finding relevant text units. Information extraction is a complex task that maps unstructured text into a variable or a structure with multiple slots and fillers.
 |
8.2.1 Characterization of Questions
Questions are distinct from statements at every level. Question syntax often uses distinct words, such as who, what, when, where, why, and how (called “wh-words”). They also have different linear order, such as putting the auxiliary verb before the main verb: “Is that a duck?”, or moving a wh-expression to the front as in “What food does a duck eat?” or “In what drawer did you put my socks?” Recognizing the expected answer type (EAT) depends on the syntax and semantics of the question. For example, a “who” question expects the name of a person, or a very specific description of an individual or group of people (e.g., “the Congress of the United States”); a “what” question expects a (nonhuman) object or idea; a “when” question expects a time (or a description of temporal constraints); a “where” question expects a name or description of a location; a “why” question expects an explanation. Representations of the meanings of questions may involve operators that indicate the type of question (Y/N vs WH), or designated quantified variables in a logical expression or, in a procedural semantics, the specification of a function that will retrieve or display information rather than store it. (For example, in an SQL representation, we would use SELECT to retrieve infromation and INSERT INTO to store it.) Question answering, like other forms of discourse, may also involve making inferences from background beliefs (such as what is already known or possessed) and forward-looking inferences about the intended goal of having an answer. An example of an inference would be when people are in a cooperative conversation with a travel agent, they can expect that a “I need the price of a train from Milwaukee to Chicago” will be treated as a wh-type question, like “What is the price of a ticket to Chicago?”
8.2.2 Characterization of Answers
Answers are distinct from statements in isolation. The form of an answer may be a single word, a short phrase, or a complete sentence. The abbreviated forms are possible because dialog participants can expect that an answer will be understood in the context of the question, and that answer semantics “inherit” the semantics of the question that prompted it. For example, a question that asks “What does a duck say?” can be answered with just “Quack”, which should be interpreted as “A duck says quack”. Answers also have implicit meaning, corresponding to the normal entailments derivable from discourse, based on cooperativeness, word meanings, and the fact that language use is a form of rational behavior (see Chapter 7). In cooperative interaction, it is the responsibility of the answer provider to assure that any obvious false inferences are not derivable from the answer [4]; for all other interactions, it is up to the questioner to decide if the respondent is being misleading.
8.3 Text Retrieval
Text retrieval systems, such as search engines, map an information need to a written document or list of documents sorted by a measure specific to the goals of the system. This measure is typically a combination of relevance to a need, information quality, and business goals (e.g., driving sales). The earliest models of text retrieval followed the organization of libraries and search methods of expert librarians. Automated methods were first introduced to handle large domain-specific collections, especially for law and medicine. The massive scale of these collections relative to the computing power of the time created a need for shallow methods capable of filtering and sorting through large collections in a relatively short amount of time[5]. These shallow methods include counting words, or short sequences of words, that occur in each document and across a collection as a whole. The methods did not include syntactic or semantic processing of the documents, and except for small sets of a few adjacent words, the order of words generally was ignored. The scale also necessitated a division of labor between tasks that are done offline, such as creating data structures that facilitate document access and tasks that are done online, such as accessing stored data structures and presenting the results as a ranked list.
Figure 8.3 illustrates the architecture of a typical text retrieval system[6]. The main components are indexing, query processing, search, ranking, and display of results. We will consider each of these in turn, moving top to bottom and then left to right across the figure.
Indexing processes a collection of documents and builds a table that associates each term (word) in a vocabulary with the set of items from the collection in which it occurs. This type of table is called a postings file, or an “inverted” index, because the normal way people think of an index is to map from a document or chapter to the words. In the process of indexing, the system will also score the importance of each term for each of the documents in which it occurs.
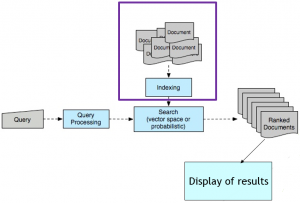 |
Query processing takes the input from the user (which we call a query) and performs standardization and generalization steps to improve the likelihood of a finding a match between the inferred intent and the documents that are retrieved. Terms in a query may be removed if they are too general (based on a hand-created “stoplist”) or terms may be added, such as synonyms from a thesaurus (“query expansion”). Sometimes unrelated terms are added on the basis that they were frequent in the top-ranked matched documents of the original query (“pseudo-relevance feedback”), which is one method of biasing the search towards one sense of an ambiguous term. Terms may also be reordered for efficiency. For example, when the results of queries with multiple terms conjoined by “and” are merged via an intersection operation, the smallest sets of results are merged first, decreasing the number of steps.
Search, also called matching, uses the processed query to find (partially) matching documents within the index and assigns them a score, typically based on the number of terms matched and their importance.
Ranking sorts the matched items according to a function that combines the search score with other proprietary factors. Ranking is a critical component, as it has been shown that many users never look beyond the first page results and instead will try a different query when the results do not appear to match their need[7]. Thus, many methods focus solely on the task of reranking the results of a less complex retrieval method.
A display of results presents the ranked results, along with other information about them. The information to be displayed is selected and formatted to help the user understand the result, such as what the document might contain and why it was ranked highly. For example, search terms may be highlighted using bold font, and spans of text that contain the terms may be extracted and concatenated so that more of them can be shown on a single page. Another type of display, called facetted, arranges the search results into categories, using terms from the retrieved documents. For example, a search for t-shirts might return a page with tabs to filter products by price, style (e.g., short-sleeve or v-neck), or sale items.
The role of natural language processing in the typical IR architecture is very limited. Morphological analysis and part of speech tagging are sometimes used in the standardization and generalization steps when creating an index and when processing the query. Natural language generation is sometimes used as a step in displaying the results. A stronger influence has been from IR to NLP, as now NLP uses much more statistical analysis of text and models text with vectors, both of which originated as ways to model documents efficiently (discussed below). However, today, the concept of using vectors as a representation has been extended to the word and sentence level, and the values of the vector elements are learned as a parameter in an optimization process, rather than direct counting of terms, as typical of text retrieval approaches.
8.3.1 Vector Spaces for Text Retrieval
In the Vector Space Model (VSM)[8] of text retrieval, both documents in the collection and queries from users are represented as vectors. Each vector has N elements (dimensions), where each dimension corresponds to a distinct word type. A word type might be a syntactic root, or a stem, which is substring of the original word that need not be an actual word. They are derived during a linear traversal of all documents in the collection. For each dimension, for each document, the value will be zero when the word type does not occur in the document; otherwise it will be a weight corresponding to the importance of the word type for discriminating among different documents that might match the inferred intent of the query. Weights for document and query vectors are computed as a combination of measures that are derived from two types of counts: a count of the number of times that a term occurs in a document, called term frequency, and a count of the number of times that a term occurs across a collection of documents, called document frequency[9]. Having higher term frequency generally corresponds to higher importance; having higher document frequency corresponds to lower importance (for discriminating between documents). The actual measure used as a weight is called tf-idf, which is calculated as the product of the term frequency and the log of the inverse document frequency. The log is used as otherwise the numbers would be too small to represent accurately by current computers for large document collections. Sometimes small numbers are added to the numerator and denominator of the fraction used to compute inverse document frequency, to reduce the impacts of documents that vary significantly in overall length across the collection, or when there are documents where a term never occurs.
Scoring the relevance of a document to the inferred intent can be calculated as the difference between the weight vectors, such as the “cosine distance” (discussed in Chapter 2), or a variant that tries to normalize for various factors that can skew the results, such as differences between the overall lengths of documents or terms that do not occur in some documents. Current search engine libraries, such as Lucene, and tools based on it, such as ElasticSearch, now use a complex measure, derived from tf-idf, known as Okapi BM25 (for “Best Match 25”) as the default function for scoring the match between queries and documents[10]. It has additional parameters to account for the average length of documents across a collection and to allow adjustments to the balance between term frequency and document frequency.
8.3.2 Evaluation of Text Retrieval Systems
Query processing and ranking methods are optimized by developers to enhance their performance. Standard measures of performance for text retrieval combine two primary measures: recall, and precision. Recall is the fraction of the total number of documents that should have matched that were actually retrieved, so the denominator is the total number of positives in the data set. Precision is the fraction of the set of retrieved results that are actually true examples, so the denominator is the total number of documents returned. In both precision and recall, the numerator is the number of relevant items returned, called the true positives. Accuracy is the sum of the proportion of the relevant things returned and the proportion of irrelevant things not returned. (Accuracy alone is rarely useful however, because typically the number of irrelevant items is many orders of magnitude greater than the number of relevant items and thus a system could just return false all the time and achieve high accuracy.) Another derived measure is called the F1 measure. F1 is the harmonic mean of the precision and recall, which, when simplified, is equivalent to two times the product of precision and recall divided by their sum. For most evaluations, F1 is used because it balances precision and recall and stays in the range 0 to 1, in a way that works better for most text retrieval than a simple average of the two values.
Other measures are sometimes used when trying to compare systems with different recall results or to better predict the experience of users, who typically make multiple queries. These other measures include Mean Average Precision (MAP) and precision and recall at rank. MAP measures the precision averaged over all levels of recall. MAP is used in many shared task challenges, where recall is determined using results pooled from all the participants. The precision and recall at rank measures are useful for comparing ranking methods, where only the top ranked items are compared. If precision and recall are measured for just the top N ranked subsets of items, this is called “precision at rank N” and “recall at rank N”, respectively. These values are useful from a practical point of view, because many people never look beyond elements that rank 10 or less when using a search engine; instead they prefer to try a new query.[11]
Precision and recall both depend on some external measure of relevance to use as a “gold standard”. Relevance judgement is a type of binary classification problem: sometimes the class can be derived from part of the data itself, but sometimes it is added manually by asking people to follow an annotation guideline. Kappa, Krippendorff’s alpha, and confusion matrices are all methods of assessing agreement for hand-labelled data. For example, Kappa is used for binary judgements involving two judges, and is computed as shown in Figure 8.4, where relevance corresponds to the label “Y” and irrelevant corresponds to the label “N”. Software libraries for training classification models, such as scikit-learn, include functions for computing precision, recall, F1, Kappa, and a variety of alternative measures for special circumstances.[12]
| Observed agreement | [(# both Judges said Y) + (# both Judges said N)] ÷ (# of samples) |
| Expected agreement | square(Estimated Probability_Y) + square(Estimated Probability_N) |
| Estimated Probability_Y | [(# Judge 1 said Y) + (# Judge 2 said Y) ] ÷ [2* (# of samples)] |
| Estimated Probabillty_N | [(# Judge 1 said N) + (# Judge 2 said N) ] ÷ [2* (# of samples)] |
| Kappa | [ObservedAgreement−ExpectedAgreement] ÷ (1−ExpectedAgreement ) |
8.3.3 Software for Information Retrieval
8.4 Information Extraction
Information extraction (IE) involves identifying entities within unstructured text and organizing them into (predefined) structures that can be used as input to downstream tasks, such as QA or summarization. IE may extract a single entity or it may extract several to fill multiple roles in a structure at once. Single entities or “factoids” include simple attributes of objects (such as its proper name, its size, or its superordinate type in an abstraction hierarchy). Examples of composite structured descriptions include specifications of events, which might include the agent, the object, and various attributes. We will consider two cases of information extraction: task-dependent information extraction and open information extraction.
8.4.1 Task-Dependent Information Extraction
In traditional, task-dependent information extraction, structures are defined by the knowledge engineer or software developer, for example to populate a database with a fixed schema. An example of a complex event would be when one company merges with another (a “merger event”) or one executive of a company is replaced by another (a “succession” event). A structure for describing a succession event might be as shown in Figure 8.5, where an empty template is shown on the left, and a filled one on the right. The candidates for the different slots would be determined using a combination of named entity recognition and some rule-based filtering. Systems that use named entity recognition can use either predefined types, or can retrain an existing model to recognize new types of entities. Formats for retraining data is often the BIO encoding of individual words, to indicate the start and continuation of each entity type. Training data for retraining the spaCy NER model is given a list where each training example is a tuple of the text and a dictionary that provides a list of entities comprising the start and end indices of the enity in that text, and the category for the named entity, e.g., ("Cats sleep a lot", {"entities": [(0, 3, "PET")]}).
| Example text | Filled template | |
|
|
8.4.2 Open Information Extraction
Open information extraction (also called relation extraction or script inference) aims to convert text into simple triples of a relation and its two arguments based simply on the semantics and proximity of the words. The goal is to enable the prediction of a missing argument, when given a relation and either one of the arguments (as a query). The relation is usually taken to be the verb itself. Figure 8.6 shows example output from the online versions of the Open IE software from AllenNLP[17], which is a reimplementation of a system by Stanovsky et al[18], at the top, and shown at the bottom, from Stanford CoreNLP[19].
| Sentence | Extreme weather is battering the Western United States, with fires raging along the Pacific Coast and snow falling in Colorado. | |||
| AllenNLP |
|
|||
| Stanford CoreNLP |
|
Identification of the arguments can be performed as a chunking task, using either search-based matching with regular expressions or a classification-based approach that classifies the starting point and continuations, based on similarly labelled training data. Alternatively, some implementations use structured classification and train on data that includes syntactic dependency structures. Examples of structured classification for OIE include the work of Chambers and Jurafsky[20], Jans et al.[21] and Pichotta and Mooney[22],[23] and Osterman et al.[24]. The most recent versions use Deep Learning approaches, such as LSTM language modelling.
8.5 Argumentation Mining
Argumentation mining (AM) is an extraction task specialized for multi-sentence texts that present a particular claim or point of view along with statements that are intended to increase or decrease the acceptability of that claim for the intended audience. A canonical example would be a legal argument, where the statements brought to bear might describe relevant legal statutes, physical evidence collected at the scene, or reported observations of witnesses. In legal terms, the primary statement being asserted is the “claim” and the other statements are known as “premises”. The relevant statutes would be the “warrant”. The structure of such arguments is similar to the type of discourse-level analysis provide by Rhetorical Structure Theory[25]. In particular graphs are used to represent the supporting and attacking relationships between statements of an argument. Potential applications of AM are still emerging, such as to gain a deeper understanding of reviews of products and services or to better understand how the general public perceives important issues of the day and what arguments would be most persuasive to changing damaging behavior. One recent example involves detecting false claims by politicians[26], [27].
Classification tasks for argumentation include identifying the boundaries of constituent elements and the argumentative relationships that hold among elements[28]. There are many common forms of argument that might be recognized, such as argument from analogy. Two markup languages have been developed for creating datasets, the Argument Markup Language[29][30] and Argdown[31], a variant of Markdown.
Argumentation Mining is considered a much harder task than generic information extraction or event mining, because argumentation structures can be nested recursively. That is, a complete argumentation structure (claim and premises) might function as the premise of some more general claim, and so on. Recognizing the relationships among components of an argument also requires real-world knowledge, including knowing when one thing is a subtype of another. In the example shown in Figure 8.7, from Moens (2018)[32], the second sentence provides evidence for the claim which appears first, but requires real-world knowledge that a cellphone is a type of communication device.
|
[CLAIM Technology negatively influences how people communicate.] [PREMISE Some people use their cellphone constantly and do not even notice their environment.] |
8.6 Summary
- McRoy, S., Rastegar-Mojarad, M., Wang, Y., Ruddy, K. J., Haddad, T. C., and Liu, H. (2018). Assessing Unmet Information Needs of Breast Cancer Survivors: Exploratory Study of Online Health Forums using Text Classification and Retrieval. JMIR Cancer, 4(1), e10. ↵
- See for example, Purkayastha, S. (2019) Top 10 Best Search API's. Web article. URL: https://blog.api.rakuten.net/top-10-best-search-apis/ Accessed August 2020. ↵
- Moldovan, D., Harabagiu, S., Pasca, M., Mihalcea, R., Girju, R., Goodrum, R. and Rus, V. (2000). The Structure and Performance of an Open-Domain Question Answering System. In Proceedings of the 38th Annual Meeting of the Association for Computational Linguistics, pp. 563-570. ↵
- Joshi, A., Webber, B. and Weischedel, R. (1984). Preventing False Inferences. In Proceedings of the 10th International Conference on Computational Linguistics and 22nd Annual Meeting of the Association for Computational Linguistics ,pp. 134-138. ↵
- Greenberg, S. J., & Gallagher, P. E. (2009). The Great Contribution: Index Medicus, Index-Catalogue, and IndexCat. Journal of the Medical Library Association 97(2), 108–113. https://doi.org/10.3163/1536-5050.97.2.007 ↵
- Jurafsky, D., & Martin, J. H. (2008). Speech and Language Processing: An introduction to speech recognition, computational linguistics and natural language processing. Upper Saddle River, NJ: Prentice Hall. ↵
- Spink, A., Wolfram, D., Jansen, M.B. and Saracevic, T. (2001). Searching the Web: The Public and Their Queries. Journal of the American Society for Information Science and Technology, 52(3), pp. 226-234. ↵
- Salton, G., Wong, A. and Yang, C.S. (1975). A Vector Space Model for Automatic Indexing. Communications of the Association for Computational Machinery, 18(11), pp.613-620. ↵
- Jones, K.S. (1973). Index Term Weighting. Information Storage and Retrieval, 9(11), pp.619-633. ↵
- Pérez-Iglesias, J., Pérez-Agüera, J.R., Fresno, V. and Feinstein, Y.Z. (2009). Integrating the Probabilistic Models BM25/BM25F into Lucene. ArXiv preprint arXiv:0911.5046. ↵
- Jansen, B.J. and Spink, A. (2006). How are We Searching the World Wide Web? A Comparison of Nine Search Engine Transaction Logs. Information Processing & Management, 42(1), pp.248-263. ↵
- Scikit-learn Developers. (2020). Metrics and Scoring: Quantifying the Quality of Predictions, Web Page, URL https://scikit-learn.org/stable/modules/model_evaluation.html Accessed August 2020. ↵
- Białecki, A., Muir, R., Ingersoll, G., and Imagination, L. (2012). Apache Lucene 4. In SIGIR 2012 Workshop on Open Source Information Retrieval (p. 17). ↵
- Apache Lucene (2021) website URL https://lucene.apache.org/ ↵
- Apache SOLR (2021) website URL https://solr.apache.org/ ↵
- Elasticsearch B.V. (2021) website URL https://www.elastic.co/ Accessed July 2021 ↵
- AllenNLP 2020, Open Information Extraction, URL: https://demo.allennlp.org/open-information-extraction Accessed September 2020. ↵
- Stanovsky, G., Michael, J., Zettlemoyer, L., and Dagan, I. (2018). Supervised Open Information Extraction. In Proceedings of the 16th Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, . ↵
- Angeli, G., Premkumar, M.J.J. and Manning, C.D. (2015). Leveraging Linguistic Structure for Open Domain Information Extraction. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pp. 344-354. ↵
- Chambers, N. and Jurafsky, D., (2008). Unsupervised Learning of Narrative Event Chains. In Proceedings of ACL/HLT 2008, pp. 789-797. ↵
- Jans, B., Bethard, S., Vulić, I. and Moens, M.F. (2012). Skip N-grams and Ranking Functions for Predicting Script Events. In Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics, pp. 336-344. ↵
- Pichotta, K. and Mooney, R. (2014). Statistical Script Learning with Multi-Argument Events. In Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics, pp. 220-229. ↵
- Pichotta, K. and Mooney, R. J. (2016). Using Sentence Level LSTM Language Models for Script Inference. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL-16), Berlin, Germany. ↵
- Ostermann, S., Roth, M., Thater, S. and Pinkal, M. (2017). Aligning Script Events with Narrative Texts. In Proceedings of the 6th Joint Conference on Lexical and Computational Semantics (SEM 2017) pp. 128-134. ↵
- Peldszus, A. and Stede, M. (2013). From Argument Diagrams to Argumentation Mining in Texts: A Survey. International Journal of Cognitive Informatics and Natural Intelligence, 7(1), pp.1-31. ↵
- Naderi, N. and Hirst, G. (2018). Automated Fact-Checking of Claims in Argumentative Parliamentary Debates. In Proceedings of the First Workshop on Fact Extraction and Verification (FEVER), Brussels, pp. 60–65. ↵
- Naderi, N. (2020) Computational Analysis of Arguments and Persuasive Strategies in Political Discourse (PhD thesis). Available online URL: https://tspace.library.utoronto.ca/bitstream/1807/101043/4/Naderi_Nona_%20_202006_PhD_thesis.pdf ↵
- Walton, D. and Macagno, F. (2016). A Classification System for Argumentation Schemes, Argument & Computation, DOI: 10.1080/19462166.2015.1123772 ↵
- Reed, C. and Rowe, G. (2001). Araucaria: Software for Puzzles in Argument Diagramming and XML. Technical Report, Department of Applied Computing, University of Dundee. ↵
- Reed, C., Mochales Palau, R., Rowe, G. and Moens, M.F. (2008). Language Resources for Studying Argument. In Proceedings of the 6th Conference on Language Resources and Evaluation LREC 2008, pp. 2613-2618. ↵
- Voigt, C. (2014). Argdown and the Stacked Masonry Layout: Two User Interfaces for Non-Expert Users. Computational Models of Argument In Proceedings of COMMA 2014, 266, p.483. ↵
- Moens, M.F. (2018). Argumentation Mining: How can a Machine Acquire Common Sense and World Knowledge?. Argument & Computation, 9(1), pp.1-14. ↵
