3 Overview of English Syntax
The order in which words and phrases occur matters. Syntax is the set of conventions of language that specify whether a given sequence of words is well-formed and what functional relations, if any, pertain to them. For example, in English, the sequence “cat the mat on” is not well-formed. To keep the set conventions manageable, and to reflect how native speakers use their language, syntax is defined hierarchically and recursively. The structures include words (which are the smallest well-formed units), phrases (which are legal sequences of words), clauses and sentences (which are both legal sequences of phrases). Sentences can be combined into compound sentences using conjunctions, such as “and”.
The categories of words used for NLP are mostly similar to those used in other contexts, but in some cases they may be different from how you were taught when you were learning the grammar of English. One of the challenges faced in NLP work is that terminology for describing syntax has evolved over time and differs somewhat across disciplines. If one were to ask how many categories of words are there, the writing center at a university might say there are eight different types of parts of speech in the English language: noun, pronoun, verb, adjective, adverb, preposition, conjunction, and interjection[1]. The folks who watched Schoolhouse Rock also were taught there were eight, but a slightly different set[2]. By contrast, the first published guideline for annotating part of speech created by linguists used eighty different categories[3]. Most current NLP work uses around 35 labels for different parts of speech, with additional labels for punctuation.
The conventions for describing syntax arise from two disciplines: studies by linguists, going back as far as 8th century BCE by the first Sanskrit grammarians, and work by computational scientists, who have standardized and revised the labeling of syntactic units to better meet the needs of automated processing. What forms a legal constituent in a given language was once determined qualitatively and empirically: early linguists would review written documents, or interview native speakers of language, to find out what phrases native speakers find acceptable and what phrases or words can be substituted for one another and still be considered grammatical. This technique is still useful today as a means of verifying the syntactic labels of rarely seen expressions. For example, in the sentence “I would rather deal with the side effects of my medication”, one might wonder if “with” is part of a complex verb “deal with” or it acts as a preposition, which is a function word more associated with the noun phrase “the side effects”. The fact that we can substitute the verb “tolerate” for “deal with” is evidence that “deal with” is a single entity.
There is always some risk of experimental bias when we depend on the judgements of untrained native speakers to define the legal structures of a language. As an alternative, there have been attempts to use evidence of language structure obtained directly from physical monitoring of people’s eyes (via eye tracking) or brains (via event-related potentials measured by electroencephalograms) while they process language. Although such physiological evidence is less subject to bias, the cost of the equipment and the difficulty of using it has limited the scale of such studies. Moreover, both of these physiological approaches rely on experts to hypothesize about the structure of language, conduct experiments to elicit human behavior, and then generalize from a relatively small set of observations.
3.1 The Role of Corpora in Understanding Syntax
Today, best practice for many subtasks of natural language processing involves working with large collections of text, each of which comprises “a corpus”. Early on in the advent of computers, some researchers surmised the importance of collecting unsolicited examples of naturally occurring text and performing quantitative analyses to inform our understanding. In the 1960’s, linguists from Brown University created the first “large” collection of text[4]. This collection is known as the Brown Corpus. It includes 500 samples of English-language text, totaling roughly one million words, compiled from works published in the United States in 1961. The words of the corpus were then annotated with part-of-speech labels, using a combination of automated labeling and laborious hand correction[5]. Although this corpus is no longer considered large, it still provides a useful benchmark for many studies and is available for use within popular NLP tools such as NLTK (with updated part-of-speech tags). Also, the technique of combining automated processing and manual correction is still often necessary.
The second large-scale collection and annotation of natural language data began in the early 1990’s with a project conducted by a team at the University of Pennsylvania, led by a Computer Scientist, Mitchell Marcus, an expert in automated sentence processing. This data set is called “the Penn Treebank” (PTB), and is the most widely used resource for NLP. This work benefited from a donation of three years of Wall Street Journal (WSJ) text (containing 98,732 news stories representing over 1.2 million word-level tokens), along with past efforts to annotate the words of the Brown Corpus with part-of-speech tags. Today, the PTB also includes annotations for the “Switchboard” corpus of transcribed spoken conversation. Switchboard includes about 2,400 two-sided telephone conversations, previously collected by Texas Instruments in the early 1990’s[6]. However, the WSJ subset of the Penn treebank corpus is still among the largest and most widely used data sets for NLP work. The word-level categories used in the PTB are very similar to those previously used by linguists, but with changes to suit the task at hand: labels were chosen to be short, but also easy for annotators to remember. Special categories were added for proper nouns, numbers, auxiliaries, pronouns, and three subtypes of wh-words, along with common variants for tense and number.
Another important English language resource is the English Web Treebank[7], completed in 2012. It has 254,830 word-level tokens (16,624 sentences) of web text that has been manually annotated with part-of-speech tags and constituency structure in the same style as the PTB. The corpus spans five types of web text: blog posts, newsgroup threads, emails, product reviews, and answers from question-answer websites. It has also been annotated with dependency structures, in the style used in the Stanford dependency parser[8].
The most recent widely used English language corpus is OntoNotes Release 5.0, completed in 2013. It is a collection of about 2.9 million words of text spread across three languages (Arabic, Chinese, and English)[9]. The text spans the domains of news, conversational telephone speech, weblogs, Usenet newsgroups, broadcast, and talk shows. It follow the same labelling conventions used in the Penn Treebank, and also adds annotations based on PropBank, which describe the semantic arguments associated with verbs. OntoNotes has been used to pretrain language models included in the spaCy NLP software libraries[10]. It includes words that did not exist when the Penn Treebank was created such as “Google”[11]. Another large, but less well known corpus, is the Open American National Corpus (OANC) which is a collection of 15 million words of American English, including texts spanning a variety of genres and transcripts of spoken data produced from 1990 through 2015. The OANC data and annotations are fully open and unrestricted for any use.[12]. Another well-known, large annotated collection of newswire next is Gigaword[13].
Terminology for describing language has become more standardized with the availability of larger corpora and more accurate tools for automated processing. Today, nearly every form of human communication is available in digital form, which allows us to to analyze large sets of sentences, spanning a wide variety of genres, including professional writing in newspapers and journal articles, informal writing posted to social media, and transcripts of spoken conversations and government proceedings. Large subsets of these texts have been annotated with grammatical information. With this data, the existence of linguistic structures and their distribution has been measured with statistical methods. This annotated data also makes it possible to create algorithms to analyze many sentences automatically and (mostly accurately) without hand-crafting a grammar.
For NLP analysis, there are four aspects of syntax that are most important: the syntactic categories and features of individual words, which we also call their parts of speech; the well-formed sequences of words into phrases and sentences, which we call constituency; the requirements that some words have for other co-occurring constituents, which we call subcategorization; and binary relations between words that are the lexical heads (main word) of a constituent, which we call lexical dependency, or just “dependency”. In this chapter, we will discuss each of these four aspects. Along with our discussion of the parts of speech, we will consider part-of-speech tags, which are the labels that NLP systems use to designate combinations of the syntactic category of a word and its syntactic features. (Some systems also use a record structure with separate fields for each feature, as an internal structure, but specialized tags are more compact for use in annotated datasets.)
3.2 Word Types and Features
3.2.1 Nouns, Pronouns, and Proper Nouns
Nouns are used to name or describe entities, which might be physical (such as “cat” or “rock”) or abstract (such as “freedom” or “laughter”) or both (such as “city” or “company”). Nouns can be singular or plural. The plural form is usually marked with the suffix “s” or “es”, as in “cats”; if a word ends in “y”, it is changed to “i” before adding the suffix. Figure 3.1 includes several examples. Some plurals are irregular, as in “children” or “knives”. Figure 3.2 includes examples of irregular nouns. Some nouns (called “count” nouns), unless they are plural, require a determiner or cardinal number to specify the denoted set, e.g. “the boy” or “three boys”. Nouns occur in the subjects of sentences and as objects following a verb or preposition. Figure 3.3 shows the typical placement of nouns within a simple sentence.
| Singular form | Regular plural form |
|---|---|
| frog | frogs |
| idea | ideas |
| fly | flies |
| fox | foxes |
| class | classes |
| Singular form | Irregular plural form |
|---|---|
| child | children |
| sheep | sheep |
| goose | geese |
| knife | knives |
| Noun in the subject | Main verb | Noun in an object | Noun in a prepositional phrase |
|---|---|---|---|
| The boy | put | his towel | in his locker |
There are some subtypes of nouns, namely proper nouns and pronouns, that are so different from common nouns that annotation for NLP treats them as separate categories, although they occur in similar contexts.
Proper nouns are the names of people, places, and things and are capitalized wherever they occur, as in “My name is Susan”. Proper nouns rarely appear as plurals, but since they sometimes do, as in “We visited the Smiths”, NLP systems include a category for plural proper nouns.
Pronouns are used to refer to people and things that have been mentioned before or presupposed to exist. They have different forms to specify whether they are singular or plural and their syntactic role (subject or object). In a grammatical sentence, the form should agree with the properties of the verb, although current NLP systems often ignore these features and only use only one category. One subclass of pronouns that is distinguished are those that express possession, and can be used in place of a determiner, e.g., “my book” or “your house,” and this subclass may also be assigned a separate part of speech. Also, some pronouns are used to form a question and thus also merit their own labels. They include both regular wh-pronouns, including “what”, “who”, and “whom,” and possessive wh-pronouns, such as “whose”.
Common nouns and proper nouns are considered an open class of words, which means people may invent new ones to describe new objects or names. By contrast, pronouns are considered a closed class of words. With open-class words, algorithms must address that new items might occur that will be outside of the known vocabulary.
3.2.2 Determiners
Determiners include “the”, “a”, “an”, “that”, “these”, “this”, and “those”. There are also determiners that are used in questions, such as “what” and “which”. Determiners only occur in noun phrases, before any adjectives or nouns. Some common nouns, when they express a mass quantity, like “water” or “rice”, or when they are plural like “cats”, do not require a determiner. Proper nouns generally do not allow a determiner, except when they are plural, e.g., “The Smiths” or when it is part of the name itself, e.g., “The Ohio State University”. Possessive phrases, which are marked with an apostrophe and the suffix “-s”, can take the place of a determiner, as in the phrase “my mother’s house”. Pronouns, regular or possessive, are never preceded by determiners. Determiners are considered a closed class of words.
3.2.3 Verbs and Auxiliary Verbs
Verbs are usually tensed (past, present, future). They include both verbs where the tensed forms are regular (see Figure 3.4) or irregular (see Figure 3.5). Also, in some contexts, verbs can appear untensed, such as after an auxiliary or after the word “to”. Verbs are also marked for number (singular or plural), and for person. First person is “I”; second person is “you”; and third person is “he”, “she”, or “it”. The third-person singular form is marked with “-s”; the non-3rd person singular present looks the same as the root form. Verbs also have participle forms for past (eg., “broken” or “thought”) and present (e.g., “thinking”).
Some verbs require a particle which is similar to a preposition except that it forms an essential part of the meaning of the verb that can be moved either before or after another argument, as in “she took off her hat” or “she took her hat off”.
Verbs that can be main verbs are an open class. Verbs that are modals or auxiliary verbs (also called helping verbs) are a closed class. They are used along with a main verb to express ability (“can”, “could”), possibility (“may”, “might”), necessity (“shall”, “should”, “ought”), certainty (“do”, “did”), future (“will”, “would”), past (“has”, “had”, “have”, “was”, “were”). NLP systems treat modals and auxiliaries as a separate part of speech. They are also all irregular in the forms that they take for different combinations of features, such as past, plural, etc. For example, the modal “can” uses the form “can” for any value for number and “could” for any value for “past”.
| Example | Regular Forms | Suffix | Features |
| walk | walks; walked; walking | -s; -ed; -ing | 3rd person singular, present; past; participle |
| Example | Irregular forms | Features |
| break | broke; broken | past; past participle |
| eat | ate; eaten | past; past participle |
| sit | sat; seated | past; past participle |
3.2.4 Prepositions
Prepositions, such as “with”, “of”, “for”, and “from” are words that relate two nouns or a noun and a verb. Prepositions require a noun phrase argument (to form a prepositional phrase). It is estimated that there about 150 different prepositions (including 94 one-word prepositions and 56 complex prepositions, such as “out of”)[14]. Prepositions are generally considered a closed class, but the possibility of complex combinations suggests that algorithms might be better off allowing for out of vocabulary examples.
3.2.5 Adjectives and Adverbs
Adjectives normally modify nouns, as in “the big red book”, but may also be an argument of a verb (including forms of “be”, “feel”, “appear”, and “become”). Adjectives can also be marked as comparative (meaning “more than typical”, using the suffix “-er”) or superlative (meaning “more than any others”, using the suffix “-est”). Adverbs modify verbs, adjectives, or other adverbs. They express manner or intensity. They may be comparative (e.g., “better”) or superlative (e.g., “best”). Adverbs that end in the suffix “-ly” have been derived from a related adjective (e.g., “quickly“ is derived from “quick“).
3.2.6 Conjunctions
Conjunctions, such as “and”, “although”, “because”, “but”, “however”, “or”, “nor”, “so”, “unless”, “when”, “where”, “while”, etc. are words that join words, phrases, clauses, or sentences. They can be discontinuous, e.g,. “either … or”, “neither … nor”, “both … and”, “not only … but also”, “on the one hand … on the other (hand)”, “not just … but”, and “not only … but”. They can take modifiers, such as “particularly”, as in Figure 3.6.
| These have been among the country’s leading imports, particularly last year when there were shortages that led many traders to buy heavily and pay dearly. [wsj 1469] |
There are three major types of conjunctions: coordinating conjunctions, subordinating conjunctions, and correlative conjunctions. A coordinating conjunction (e.g., “and”, “but”, “or”, and “so”) joins two structures that have the same type. Their purpose is to express that two entities did something together, or two events happened at the same time. A subordinating conjunction (e.g., “after”, “although”, “because”, “before”, “if”, “how”, “however”, “since”, “once”, “until”, “when”, “where”, “while”, “whenever”, “as soon as”, “even if”, “no matter how”, etc) join a subordinate (dependent) and a main (independent) clause. The main clause can be understood on its own. The dependent clause can only be fully understood in the context of the main clause, as its purpose is to provide background, explanation, justification, or possible exceptions to what is said in the main clause. Thus, they express what is known as rhetorical structure or discourse relations among clauses, which can occur either within the same sentence or between adjacent sentences. When they link adjacent sentences at the sentence level, these words function as adverbs, so subordinating conjunctions are often labelled as adverbs, wherever they occur, and some experts refer to them as conjunctive adverbs. Sometimes subordinating conjunctions are labelled as prepositions, as in the Penn Treebank II. Discourse relations can exist without any explicit conjunction, but by using hand-annotated data, such as the Penn Discourse Treebank or the Biomedical Discourse Relation Bank, they can be identified using automated discourse parsing. A correlative conjunction is a discontinuous conjunction that joins words, phrases, or clauses that have a complementary relationship. Because they are discontinuous, they are harder to learn, and so automated systems do not always label them consistently. Figure 3.7 includes some sentences illustrating different types of conjunctions and how they are labelled using the default Stanford CoreNLP part-of-speech tagger.
| Example sentences | Type of expression with labels given by CoreNLP |
| You can walk but you cannot run. | Coordinating conjunction, labelled as conjunction |
| You can read at home or in the library. | Coordinating conjunction, labelled as conjunction |
| My daughter and her friends like to climb. | Coordinating conjunction, labelled as conjunction |
| My cat purrs when you pet her. | Subordinating conjunction, labelled as adverb |
| If you study hard, you will do well. | Subordinating conjunction, labelled as preposition |
| You can either walk or take the bus. | Correlative conjunction, labelled as adverb, conjunction |
| The car not only is quiet but also handles well. | Correlative conjunction, labelled adverb, adverb, conjunction, adverb |
| Embryonic Stem cells have a high mitotic index and form colonies. So, experiments can be completed rapidly and easily. | Discourse adverbial, labelled as adverb |
| Obese cats have higher levels of inflammatory chemicals in their bloodstream. However, rapid shifts in fat tissue further increase this inflammation. | Discourse adverbial, labelled as adverb |
3.2.8 Wh-Words
Wh-words that begin with the letters “wh-” like “who”, “what”, “when”, “where”, “which”, “whose”, and “why” and their close cousins “how”, “how much”, “how many”, etc. They are used for posing questions and are thus sometimes called interrogatives. Unlike the word types mentioned so far, they can be determiners, adverbs, or pronouns (both regular and possessive), and so it is typical to see them marked as a special subtype of each. Identifying phrases that include wh-words is important, because they usually occur near the front in written text and fill an argument role that has been left empty in its normal position, as in “Which book did you like best?” In informal speech one might say “You left your book where?” or “You said what?”, but the unusual syntax also suggests a problem (like mishearing, shock, or criticism). The semantics of the wh-expression specify what sort of answer the speaker is expecting (e.g., a person, a description, a time, a place, etc) and thus are essential to question-answering systems.
3.3 Part-of-Speech Tags
The general syntactic category of a word is also known as its part of speech (POS) whereas “tag” refers to labels for specifying the category and syntactic features (such as singular or plural). Today, the use of “tag” is often synonymous with the labels given in the Penn Treebank II (PT2) tagset[15],[16]. There was no process of agreement for adopting this tagset as a standard. Instead, a group of linguistic experts, with resources to support the work, developed them and disseminated them widely. Along the way, refinements have been made so that human annotation is more reliable and the sets of words in each category are not too sparse; early versions had about 80 tags, while the current only has only about 35. The tag set and associated guidelines for English have been stable since 2015. (The word tags have been stable since 1999). Figure 3.8 includes the complete English tagset for words, excluding punctuation.
| Tag | Description | Example |
| CC | conjunction, coordinating | and, or, but |
| CD | cardinal number | five, three, 13% |
| DT | determiner | the, a, these |
| EX | existential there | there were six boys |
| FW | foreign word | mais |
| IN | conjunction, subordinating or preposition | that, of, on, before, unless |
| JJ | adjective | nice, easy |
| JJR | adjective, comparative | nicer, easier |
| JJS | adjective, superlative | nicest, easiest |
| LS | list item marker | 1), 2), etc |
| MD | verb, modal auxiliary | may, should |
| NN | noun, singular or mass | tiger, chair, laughter |
| NNS | noun, plural | tigers, chairs, insects |
| NNP | noun, proper singular | Milwaukee, Rex, Claire |
| NNPS | noun, proper plural | I go out on Fridays, We go to the Smiths’ |
| PDT | predeterminer | both his children |
| POS | possessive ending | ‘s |
| PRP | pronoun, personal | me, you, it, him, her |
| PRP$ | pronoun, possessive | my, your, our |
| RB | adverb | extremely, loudly, hard |
| RBR | adverb, comparative | better |
| RBS | adverb, superlative | best |
| RP | adverb, particle | about, off, up |
| SYM | symbol | %, # |
| TO | infinitival to | what to do, I want to sleep |
| UH | interjection | oh, oops, gosh |
| VB | verb, base form | think, eat |
| VBZ | verb, 3rd person singular present | she thinks, she eats |
| VBP | verb, non-3rd person singular present | I think |
| VBD | verb, past tense | they thought |
| VBN | verb, past participle | a sunken ship |
| VBG | verb, gerund or present participle | thinking is fun |
| WDT | wh-determiner | which, whatever, whichever |
| WP | wh-pronoun, personal | what, who, whom |
| WP$ | wh-pronoun, possessive | whose, whosever |
| WRB | wh-adverb | where, when |
3.4 Multi-WOrd ConstituenTS
For each of the primary types of words, there is a corresponding phrase type that includes the main word (called the “head”), along with any modifiers (optional words or phrases that enhance the meaning), or arguments (words or phrases that are required to be present). These phrases can also be combined recursively to form more complex phrases, clauses, or sentences. Below we will overview the major types of phrases and some of the conventions that define them. A complete discussion of English grammar fills a book of over 1800 pages[17]. This complexity is one reason that modern grammars are learned from large collections of text, rather than written by hand.
3.4.1 Noun Phrases and Prepositional Phrases
Noun phrases are the most used type of phrase but also have the most variation. Noun phrases can be simply a pronoun or proper noun, or include a determiner, some premodifiers (such as adjectives), the head noun, and some postmodifiers at the end. The determiner might be a single word or a complex expression such as a complete noun phrase that includes a possessive marker ( “-‘s” or “-s’ “) at the end. Gerunds are noun phrases where a verb that ends in “-ing” (tagged as VBG) acts as a head noun, as in the sentence “Walking is good exercise”.
It is common to describe noun phrases as a combination of a determiner and a nominal, where the nominal is an ordered sequence of optional premodifiers, the head, and the postmodifiers. The premodifiers can include a cardinal (such as “third”), an ordinal (such as “three”), a quantifier (such as “all” or “most”), other common nouns, an adjective, or an adjective phrase (such as “very green and slimy”). English only permits three types of postmodifiers: relative clauses (such as “the dog that found a bone” or “the dog that I got at the humane society“), non-finite clauses (such as “I had something to eat”), and prepositional phrases. Relative clauses following the head of a noun often begin with a relative pronoun, such as “that”, “which”, “who”, “whose”, “whom”, or “whomever” and sometimes also “when” or “where”[18]. Sometimes these words can be omitted. So, instead of saying “The meal that I ate was yummy” we might say “The meal I ate was yummy”. When the relative pronoun is omitted, this is sometimes described as being a reduced relative clause. Also, the head noun will always fill some syntactic role within the relative clause (either a subject or object), so a grammatical relative clause cannot also include a filler for this same role. So, one cannot say “The meal that I ate the meal was yummy.”, as it overfills the object role of “ate”.
Prepositional phrases comprise a preposition followed by a noun phrase. Semantically, we use them to add locations, times, or generic modifiers to a noun or to a sentence. They can follow a head noun or verb in a noun phrase or verb phrase, respectively. They can also modify an entire clause, where they typically occur either at the very beginning or the very end.
3.4.2 Verb Phrases
Verb phrases (VP) comprise a sequence of auxiliaries or modals, a main verb, the arguments of the main verb, and optional prepositional phrases as modifiers. Adverbs can appear almost anywhere within the VP. The arguments of a verb will depend on the verb, some take no arguments, some take one or two. An argument may also be restricted to be a particular syntactic structure such as a noun phrase or a clause, or it may be a semantic requirement, such as being a description of a location. Linguists have used case grammars[19] or slot grammars[20] to describe the argument structures of verbs. For NLP several resources have been created that are available as part of the Unified Verb Index[21]. These resources include VerbNet, FrameNet and OntoNotes. For example, VerbNet is the largest verb lexicon for English. It groups together verbs with identical sets of syntactic frames and semantic predicate structures and provides information about those structures. Syntactic frames are sometimes also called “thematic roles”. Figure 3.9 shows some of the syntactic structures associated with “cut21.1”. OntoNotes is a corpus of text that includes annotation of a wide variety of text (telephone conversations, newswire, newsgroups, broadcast news, broadcast conversation, and weblogs) with syntax, argument structure, and shallow semantics.
| Verb Pattern | Example with syntactic frame | ||
| NP V NP |
|
||
| NP V PP |
|
||
| NP V NP ADJP |
|
||
| NP V NP PP.instrument |
|
3.4.3 Clauses and Sentences
Clauses and sentences are structures that include a verb with a complete set of arguments. Sentences can either be statements (declaratives), questions (interrogatives), or commands (imperatives). Questions can either be yes-no questions (constructed by putting the auxiliary in front of the subject noun phrase) or wh-questions which include a question word at the front (“who”, “what”, “when”, “where”, “why”, “how”), and sometimes also an auxiliary before the subject noun phrase. In wh-questions the question word takes the place of some other constituent in the sentence (either a subject or an object of a verb or preposition) that is an unknown, such as the type of something. A passive sentence is one where the semantic object appears as the syntactic subject (the one before the VP) as in “The apple was eaten”. Some examples of different types of sentences are shown in Figure 3.10.
| Example sentence | Sentence type |
| The cat sat. | Statement |
| The cat chased a mouse. | Statement |
| The mouse was chased | Passive statement |
| The girl gave her cat a toy | Statement |
| The cat slept in the bed. | Statement |
| What did the cat do? | Wh – question |
| What did the cat chase? | Wh – question |
| Who gave the cat a toy? | Wh – question |
| Who did she give the toy to? | Wh – question |
| What did she give the cat? | Wh – question |
| Where did the cat sleep? | Wh – question |
| Did the cat catch the mouse? | Yes – no question |
| Is it time to put the cat outside? | Yes – no question |
| Wake up the cat. | Command |
| Wash the bed when she is done sleeping. | Command |
Clauses in English include complete declarative sentences (comprising a subject main verb and its required objects), dependent relative clauses introduced by a subordinating conjunction (e.g., “that”, “before”), interrogative sentences (i.e., questions) marked by a wh-word or by inverting the subject and the main verb or a modal, or a combination. When the wh-word at the front refers to one of the objects of the main verb or a prepositional phrase, then the normal position for that object will be empty in a grammatical sentence. Linguists refer to this phenomenon as movement and the location of the missing object is a gap or trace. In the treebank data this information is not tracked, except to note that the sentence is a question introduced by a wh-word (i.e., SBARQ). Lastly, adverbs, adjectives, and interjections can also occur as sequences of several adjacent words. Figure 3.11 shows some examples of these constructions and the category labels that are used in the Penn Treebank, and thus have become the standard for automatic processing as well.
| Tag | Description | Examples |
| NP | Noun phrase | The strange bird in the tree sang. |
| PP | Prepositional phrase | I walked in the park |
| VP | Verb phrase | I was looking around. |
| S | Sentence, declarative | The cat slept. |
| SQ | Inverted yes/no question | Did the cat sleep? |
| SBAR | Relative clause | A cat that sleeps is happy. The cat slept before she ate. |
| SBARQ | Direct questions, introduced by a wh-word | Who slept on the floor? |
| SINV | Inverted declarative sentence (subject follows tensed verb or modal) | Never has she been so happy. |
| ADVP | Adverb phrase | I am also very happy. |
| ADJP | Adjective phrase | The bed is warm and cozy. |
| QP | Quantifier phrase | She had no more than 100. |
| INTJ | Interjection with several words | Hello in there, I did not see you. |
3.5 Subcategorization
|
Example
|
Subcategorization
|
|
She was happy to get a puppy.
|
“happy” requires a VP in the infinitive form
|
|
The front of the bus was empty.
|
“front” requires a PP that starts with “of”
|
|
She said she wanted to be president.
|
“said” requires a complete S (any form)
|
3.6 Lexical dependency
An alternative to constituency for describing the legal sequences of words, is to describe sequences in terms of binary syntactic relations between a head word and an argument. These relations are called lexical dependencies or just “dependencies”. These dependencies include the categories of subject, direct object, and indirect object, and categories for different types of modifiers. Which of these arguments is required depends on the subcategorization constraints of the head word. When both a direct and an indirect object are required, the indirect object occurs first, unless it is contained inside a prepositional phrase that begins with “to”. Figure 3.13 shows examples where the main part of the dependency is marked in bold and the dependent part is marked in italics.
| Name | Description | Example |
| nsubj | nominal subject | The cat chased the mouse. |
| dobj | direct object | The cat chased the mouse. |
| iobj | indirect object | The bird fed her babies a worm. |
| iobj | indirect object | The bird fed a worm to her babies. |
| pobj | prepositional object | The bird in the tree was sleeping. |
| amod | adjective modifier | The happy bird sang. |
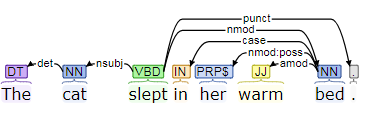
Both constituency and dependency induce a tree structure over legal sequences of words. The main difference between dependency trees and constituency trees is that dependency trees store words at every node, whereas in constituency trees only store words in the leaves, and the nodes are marked with part-of-speech tags. Figure 3.14 includes an example of the representation for the sentence, “The cat slept in her warm bed”. The dependencies include that “cat” is the noun subject of the verb “slept”, “bed” is a noun modifier of “slept”, “her” is a possessive noun modifier of “bed”, and “warm” as an adjective modifier of “bed”. (The relations “det” and “case” are the labels used for the corresponding function words.)
 |
There are currently 37 universal syntactic relations defined by the Universal Dependencies organization (See Figure 3.15).
| Universal dependency and description | Universal dependency and description |
| acl: clausal modifier of noun (adjectival clause) | fixed: fixed multiword expression |
| advcl: adverbial clause modifier | flat: flat multiword expression |
| amod: adjectival modifier | goeswith: goes with |
| appos: appositional modifier | iobj: indirect object |
| aux: auxiliary | list: list |
| case: case marking | mark: marker |
| cc: coordinating conjunction | nmod: nominal modifier |
| ccomp: clausal complement | nsubj: nominal subject |
| clf: classifier | nummod: numeric modifier |
| compound: compound | obj: object |
| conj: conjunct | obl: oblique nominal |
| cop: copula | orphan: orphan |
| csubj: clausal subject | parataxis: parataxis |
| dep: unspecified dependency | punct: punctuation |
| det: determiner | reparandum: overridden disfluency |
| discourse: discourse element | root: root |
| dislocated: dislocated elements | vocative: vocative |
| expl: expletive | xcomp: open clausal complement |
3.7 Summary
- The types and features of words,
- The constituency of legal sequences of words, or
- Dependency relations that hold between pairs of words, and
- The subcategorization constraints that some words impose on sequences of words.
- Butte College 2020. The Eight Parts of Speech. URL: http://www.butte.edu/departments/cas/tipsheets/grammar/parts_of_speech.html Accessed May 2020. ↵
- The videos can be found online. Here is one place to find them: https://www.teachertube.com/collections/school-house-rock-grammar-4728 ↵
- Francis, W. N. and Kučera, H. (1964). Manual of Information to accompany A Standard Corpus of Present-Day Edited American English, for use with Digital Computers. Providence, Rhode Island: Department of Linguistics, Brown University. Revised 1971. Revised and amplified 1979. Available online at: http://icame.uib.no/brown/bcm.html ↵
- Kučera, H. and Francis, W.N. (1967). Computational Analysis of Present-Day American English. Dartmouth Publishing Group. ↵
- Greene, B. B., and Rubin, G. M. (1971). Automatic Grammatical Tagging of English. Technical Report, Department of Linguistics, Brown University, Providence, Rhode Island. ↵
- Godfrey, J. and Holliman, E. (1993) Switchboard-1 Release 2 LDC97S62. Web Download. Philadelphia: Linguistic Data Consortium. ↵
- Beis, A., Mott, J., Warner, C., and Kulick, S. (2012). English Web Treebank LDC2012T13. Web Download. Philadelphia: Linguistic Data Consortium, 2012. URL: https://catalog.ldc.upenn.edu/LDC2012T13 ↵
- Silveira, N., Dozat, T., De Marneffe, M.C., Bowman, S.R., Connor, M., Bauer, J., and Manning, C.D. (2014). A Gold Standard Dependency Corpus for English. Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC'14), pp. 2897-2904. ↵
- Weischedel, R., Palmer, M., Marcus, M., Hovy, E., Pradhan, S., Ramshaw, L., Xue, N., Taylor, A., Kaufman, J., Franchini, M., El-Bachouti, M., Belvin, R., and Houston, A. (2013). OntoNotes Release 5.0 LDC2013T19. Linguistic Data Consortium, Philadelphia. ↵
- spacy.io (2020). spaCy English Available Pretrained Statistical Models for English. URL: https://spacy.io/models/en ↵
- Li, S. (2018). Named Entity Recognition with NLTK and spaCy URL: https://towardsdatascience.com/named-entity-recognition-with-nltk-and-spacy-8c4a7d88e7da ↵
- ANC.org (2015) Open American National Corpus URL: http://www.anc.org/ ↵
- Napoles, C., Gormley, M. R., & Van Durme, B. (2012, June). Annotated Gigaword. In Proceedings of the Joint Workshop on Automatic Knowledge Base Construction and Web-scale Knowledge Extraction (AKBC-WEKEX) (pp. 95-100). ↵
- Essberger, J. (2012). English Preposition List. Ebook Online: http://www.englishclub.com/download/PDF/EnglishClub-English-Prepositions-List.pdf ↵
- Bies, A., Ferguson, M., Katz, K., and MacIntyre, R. (1995). Bracketing Guidelines For Treebank II Style Penn Treebank Project. URL https://web.archive.org/web/20191212003907/http://languagelog.ldc.upenn.edu/myl/PennTreebank1995.pdf ↵
- Warner, C., Bies, A., Brisson, and C. Mott, J. (2004). Addendum to the Penn Treebank II Style Bracketing Guidelines: BioMedical Treebank Annotation, University of Pennsylvania, Linguistic Data Consortium. ↵
- Huddleston, R. D. and Pullum, G. K. (2002)The Cambridge Grammar of the English Language. Cambridge, UK: Cambridge University Press. ↵
- Grammars for NLP use a variety of categories for these words including wh-determiner (which, that, who, whom), wh-possessive pronoun (whose), and wh-adverb (when, where). ↵
- Fillmore, C. J., and Fillmore, S. (1968). Case Grammar. Universals in Linguistic Theory. Holt, Rinehart, and Winston: New York, pp. 1-88. ↵
- McCord, M. C. (1990). Slot Grammar. In Natural Language and Logic. pp. 118-145. Springer, Berlin, Heidelberg. ↵
- Kipper, K., Korhonen, A., Ryant, N., and Palmer, M. (2008) A Large-scale Classification of English Verbs. Language Resources and Evaluation Journal,42(1). Springer Netherland. pp. 21-40. ↵
- Yallop, J., Korhonen, A., and Briscoe, T. (2005). Automatic Acquisition of Adjectival Subcategorization from Corpora. 10.3115/1219840.1219916. ↵
Open class words are categories of words, such as nouns and action verbs, where instances may be created or discarded over time, as new concepts are imagined.
Closed class words belong to categories of words whose elements do not change, such as the pronouns and auxilliary verbs of English.
The Unified Verb Index is a federated system which merges links and web pages from four different natural language processing projects related to verbs: VerbNet, PropBank, FrameNet, and OntoNotes Sense Groupings.
